


提取 word 文档内容在工作和学习中扮演着重要角色。抽取一页内容有助于快速浏览和总结要点,而提取一个节的内容则有助于深入研究特定主题或部分内容。全文提取则使您能够全面了解文档内容,促进深入分析和全面理解。本文将介绍如何使用 spire.doc for java 在 java 从 word 文档中提取单页内容、单个节的内容以及整篇文档的内容。
安装 spire.doc for java
首先,您需要在 java 程序中添加 spire.doc.jar 文件作为依赖项。您可以从此链接下载 jar 文件;如果您使用 maven,则可以通过在 pom.xml 文件中添加以下代码导入 jar 文件。
com.e-iceblue
e-iceblue
https://repo.e-iceblue.cn/repository/maven-public/
e-iceblue
spire.doc
12.4.14
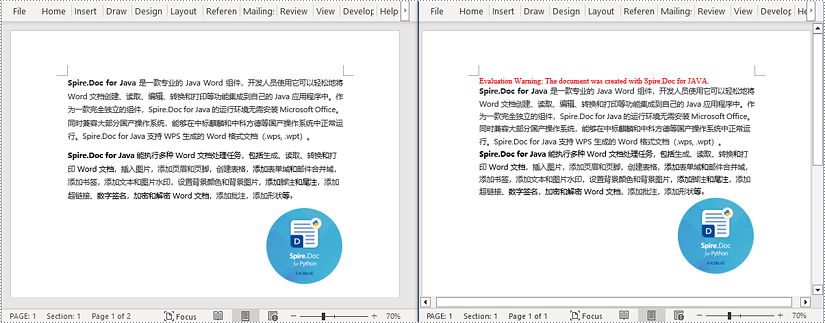
java 从 word 文档中读取一页的内容
使用 fixedlayoutdocument 类和 fixedlayoutpage 类可以方便地提取指定页面的内容。为了更便于查看提取的内容,下面的示例代码将提取的内容保存到一个新的 word 文档中。详细步骤如下:
- 创建一个 document 对象。
- 使用 document.loadfromfile() 方法加载示例 word 文档。
- 创建一个 fixedlayoutdocument 对象。
- 获取文档中的一个页面的 fixedlayoutpage 对象。
- 通过 fixedlayoutpage.getsection() 方法获取页面所在的节。
- 获取页面第一个段落在节中的索引位置。
- 获取页面最后一个段落在节中的索引位置。
- 创建另一个 document 对象。
- 使用 document.addsection() 添加一个新的节。
- 使用 section.clonesectionpropertiesto(newsection); 方法将原始节的属性克隆到新节中。
- 复制原文档中页面的内容到新文档中。
- 使用 document.savetofile() 方法保存结果文档。
- java
import com.spire.doc.*;
import com.spire.doc.pages.*;
import com.spire.doc.documents.*;
public class readonepage {
public static void main(string[] args) {
// 创建一个新的文档对象
document document = new document();
// 从指定文件加载文档内容
document.loadfromfile("示例.docx");
// 创建一个固定布局文档对象
fixedlayoutdocument layoutdoc = new fixedlayoutdocument(document);
// 获取第一个页面
fixedlayoutpage page = layoutdoc.getpages().get(0);
// 获取页面所在的节
section section = page.getsection();
// 获取页面的第一个段落
paragraph paragraphstart = page.getcolumns().get(0).getlines().getfirst().getparagraph();
int startindex = 0;
if (paragraphstart != null)
{
// 获取段落在节中的索引
startindex = section.getbody().getchildobjects().indexof(paragraphstart);
}
// 获取页面的最后一个段落
paragraph paragraphend = page.getcolumns().get(0).getlines().getlast().getparagraph();
int endindex = 0;
if (paragraphend != null)
{
// 获取段落在节中的索引
endindex = section.getbody().getchildobjects().indexof(paragraphend);
}
// 创建一个新的文档对象
document newdoc = new document();
// 添加一个新的节
section newsection = newdoc.addsection();
// 克隆原节的属性到新节
section.clonesectionpropertiesto(newsection);
// 复制原文档中页面内容到新文档
for (int i = startindex; i <=endindex; i )
{
newsection.getbody().getchildobjects().add(section.getbody().getchildobjects().get(i).deepclone());
}
// 将新文档保存为指定文件
newdoc.savetofile("读取一页的内容.docx", fileformat.docx);
// 关闭并释放新文档
newdoc.close();
newdoc.dispose();
// 关闭并释放原文档
document.close();
document.dispose();
}
}
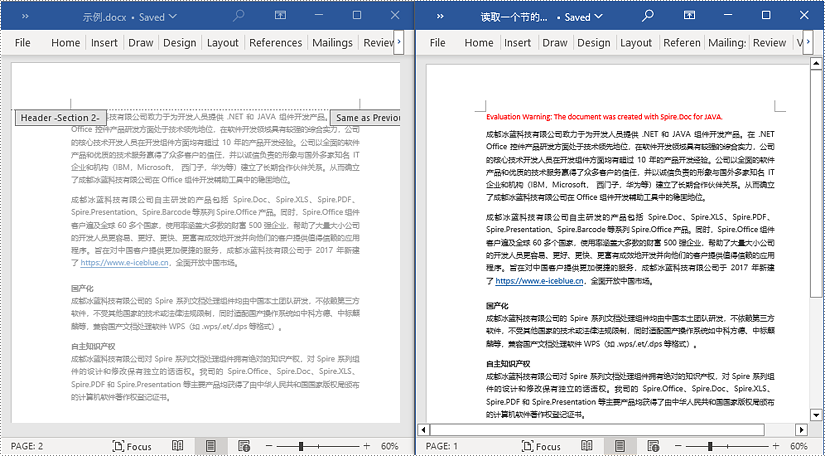
java 从 word 文档中读取一个节的内容
使用 document.sections[index] 可以访问特定的节对象,其中包含页眉、页脚和正文内容。以下示例展示了一种简单的方法,将一个节的所有内容复制到另一个文档中。详细步骤如下:
- 创建一个 document 对象。
- 使用 document.loadfromfile() 方法加载示例 word 文档。
- 使用 document.getsections().get(1) 获取文档的第二个节。
- 创建另一个新的 document 对象。
- 使用 document.clonedefaultstyleto(newdoc) 方法克隆原始文档的默认样式到新文档。
- 使用 document.getsections().add(section.deepclone()) 方法将原始文档的第二个节的内容克隆到新文档中。
- 使用 document.savetofile() 方法保存结果文档。
- java
import com.spire.doc.*;
public class readonesection {
public static void main(string[] args) {
// 创建一个新的文档对象
document document = new document();
// 从文件加载word文档
document.loadfromfile("示例.docx");
// 获取文档的第二个节
section section = document.getsections().get(1);
// 创建一个新的文档对象
document newdoc = new document();
// 将默认样式克隆到新文档
document.clonedefaultstyleto(newdoc);
// 将第二个节克隆到新文档中
newdoc.getsections().add(section.deepclone());
// 将新文档保存为文件
newdoc.savetofile("读取一个节的内容.docx", fileformat.docx);
// 关闭并释放新文档对象
newdoc.close();
newdoc.dispose();
// 关闭并释放原始文档对象
document.close();
document.dispose();
}
}
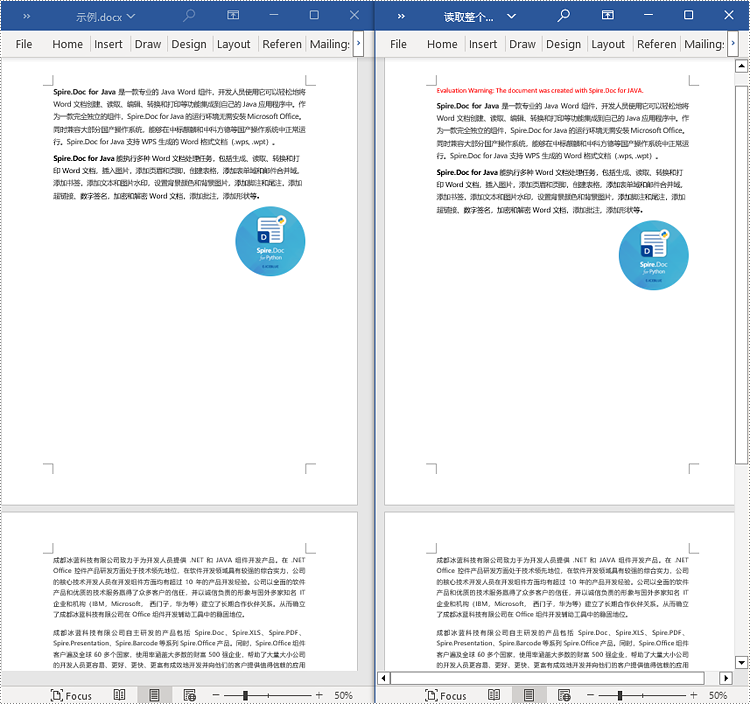
java 从 word 文档中读取整个文档的内容
这个示例演示了如何通过遍历原始文档的每个节来读取整个文档的内容,并将每个节克隆到一个新文档中。这种方法可以帮助您快速复制整个文档的结构和内容,使得在新文档中保留原始文档的格式和布局。这样的操作对于保留文档结构的完整性和一致性非常有用。详细步骤如下:
- 创建一个 document 对象。
- 使用 document.loadfromfile() 方法加载示例 word 文档。
- 创建另一个新的 document 对象。
- 使用 document.clonedefaultstyleto(newdoc) 方法克隆原始文档的默认样式到新文档。
- 使用一个 for 循环遍历原始文档中的每个节并将其克隆到新文档中。
- 使用 document.savetofile() 方法保存结果文档。
- java
import com.spire.doc.*; public class readonedocument { public static void main(string[] args) { // 创建一个新的文档对象 document document = new document(); // 从文件加载word文档 document.loadfromfile("示例.docx"); // 创建一个新的文档对象 document newdoc = new document(); // 将默认样式克隆到新文档 document.clonedefaultstyleto(newdoc); // 遍历原始文档中的每个节并将其克隆到新文档中 for (section sourcesection : (iterable)document.getsections()) { newdoc.getsections().add(sourcesection.deepclone()); } // 将新文档保存为文件 newdoc.savetofile("读取整个文档的内容.docx", fileformat.docx); // 关闭并释放新文档对象 newdoc.close(); newdoc.dispose(); // 关闭并释放原始文档对象 document.close(); document.dispose(); } }
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


