


word 中的分节符允许用户将文档划分为多个部分,每个部分都有独特的格式选项。在处理长文档时,如果想在同一文档中应用不同的布局、页眉、页脚、页边距或页面方向等,分节符是必要的元素。在本文中,您将学习如何使用 spire.doc for python 在 word 中插入或删除分节符。
安装 spire.doc for python
本教程需要用到 spire.doc for python 和 plum-dispatch v1.7.4。可以通过以下 pip 命令将它们轻松安装到 windows 中。
pip install spire.doc如果您不确定如何安装,请参考:如何在 windows 中安装 spire.doc for python
python 在 word 中插入分节符
spire.doc for python 提供了 paragraph.insertsectionbreak(breaktype: sectionbreaktype) 方法,用于在段落中插入指定类型的分节符。下表概述了支持的分节符类型及其相应的枚举和说明:
| 分节符 | 枚举 | 描述 |
| 下一页 | sectionbreaktype.newpage | 在新页面上开始新节。 |
| 连续 | sectionbreaktype.nobreak | 在同一页面上开始新节。 |
| 奇数页 | sectionbreaktype.oddpage | 在下一奇数页上开始新节。 |
| 偶数页 | sectionbreaktype.evenpage | 在下一偶数页上开始新节。 |
| 新建栏 | sectionbreaktype.newcolumn | 在下一栏中开始新节。 |
以下是插入连续分节符的详细步骤:
- 创建 document 类的对象。
- 使用 document.loadfromfile() 方法加载 word 文档。
- 使用 document.sections[] 属性获取指定的章节。
- 使用 section.paragraphs[] 属性获取指定段落。
- 使用 paragraph.insertsectionbreak() 方法在段落末尾添加分段符。
- 使用 document.savetofile() 方法保存结果文档。
- python
from spire.doc import *
from spire.doc.common import *
inputfile = "测试.docx"
outputfile = "插入分节符.docx"
# 创建document对象
document = document()
# 加载word文档
document.loadfromfile(inputfile)
# 获取文档中第一节
section = document.sections[0]
# 获取第一段
paragraph = section.paragraphs[0]
# 插入连续分节符
paragraph.insertsectionbreak(sectionbreaktype.nobreak)
# 保存结果文件
document.savetofile(outputfile, fileformat.docx2016)
document.close()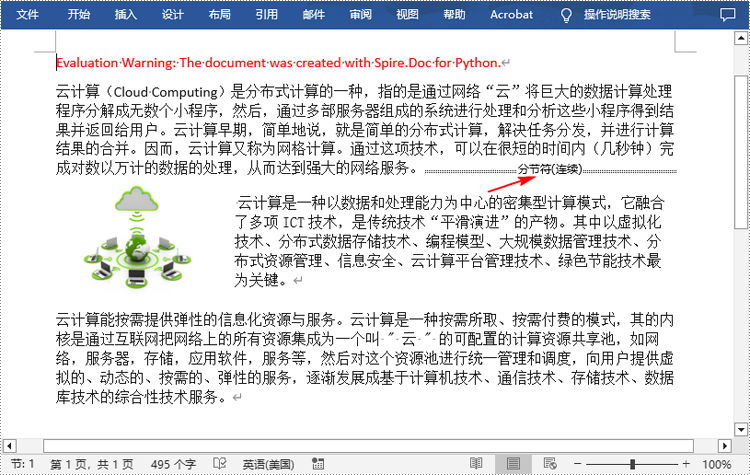
python 删除 word 中的分节符
要删除 word 文档中的所有分节符,我们需要访问文档中的第一个分节,然后将其他分节的内容复制到第一个分节后再删除。以下是详细步骤:
- 创建 document 类的对象。
- 使用 document.loadfromfile() 方法加载 word 文档。
- 使用 document.sections[] 属性获取第一节。
- 遍历文档中的其他部分。
- 获取第二节,然后遍历获取其子对象。
- 使用 section.body.childobjects.add() 方法复制第二节的子对象并将其添加到第一节中。
- 使用 document.sections.remove() 方法删除第二个部分。
- 重复上述过程,复制并删除其余分节。
- 使用 document.savetofile() 方法保存结果文档。
- python
from spire.doc import *
from spire.doc.common import *
inputfile = "实验.docx"
outputfile = "删除分节符.docx"
# 创建document对象
document = document()
# 加载word文档
document.loadfromfile(inputfile)
# 获取文档中第一节
sec = document.sections[0]
# 遍历文档中其他节
for i in range(document.sections.count - 1):
# 获取第二节
section = document.sections[1]
# 遍历第二节中所有子对象
for j in range(section.body.childobjects.count):
# 获取子对象
obj = section.body.childobjects.get_item(j)
# 将子对象复制到第一节
sec.body.childobjects.add(obj.clone())
# 移除第二节
document.sections.remove(section)
# 保存结果文档
document.savetofile(outputfile, fileformat.docx2016)
document.close()
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


